jk 露出

[新智元导读]26岁的OpenAI吹哨东谈主,在发出公开指控不到三个月,被发现死在我方的公寓中。法医认定男同 影片,死因为自裁。那么,他在死前两个月发表的一篇博文中,齐说了什么?
就在刚刚,音讯曝出:OpenAI吹哨东谈主,在家中离世。曾在OpenAI职责四年,指控公司扰乱版权的SuchirBalaji,上月底在旧金猴子寓中被发现死一火,年仅26岁。旧金山警方暗意,11月26日下昼1时许,他们接到了一通要求稽查Balaji抚慰的电话,但在到达后却发现他也曾死一火。

这位吹哨东谈主手中掌捏的信息,原来将在针对OpenAI的诉讼中施展要道作用。如今,他却无意升天。法医办公室认定,死因为自裁。警方也暗意,「并未发现任何他杀根据」。
他的X上的临了一篇帖子,恰是先容我方对于OpenAI历练ChatGPT是否违犯法律的想考和分析。他也强调,但愿这不要被解读为对ChatGPT或OpenAI自身的月旦。

如今,在这篇帖子下,网友们纷繁发出漫骂。
SuchirBlaji的一又友也暗意,他东谈主尽头颖异,毫不像是会自裁的东谈主。
吹哨东谈主警告:OpenAI历练模子时违犯原则
SuchirBalaji曾参与OpenAI参与迷惑ChatGPT及底层模子的历程。本年10月发表的一篇博文中他指出,公司在使用新闻和其他网站的信息历练其AI模子时,违犯了「合理使用」原则。
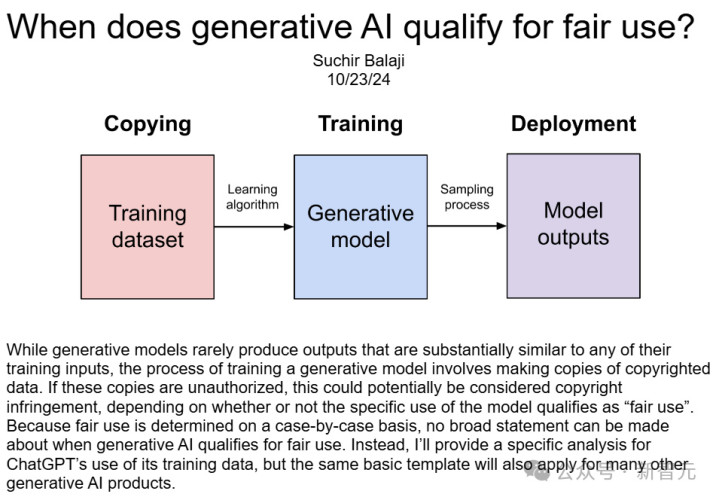
博文地址:https://suchir.net/fair_use.html但是,就在公开指控OpenAI违犯好意思国版权法三个月之后,他就离世了。
为什么11月底的事情12月中旬才爆出来,网友们也暗意质疑
其实,自从2022年底公迷惑布ChatGPT以来,OpenAI就濒临着来自作者、设施员、记者等群体的一波又一波的诉讼潮。他们以为,OpenAI犯法使用我方受版权保护的材料来历练AI模子,公司估值攀升至1500亿好意思元以上的果实,却我方独享。为此,《水星新闻报》《纽约时报》等多家报社,齐在当年一年内对OpenAI拿告状讼。本年10月23日,《纽约时报》发表了对Balaji的采访,他指出,OpenAI正在损伤那些数据被哄骗的企业和创业者的利益。「如果你认可我的不雅点,你就必须离开公司。这对悉数这个词互联网生态系统而言,齐不是一个可连续的模式。」
一个梦想主义者之死
Balaji在加州长大,十几岁时,他发现了一则对于DeepMind让AI我方玩Atari游戏的报谈,心生向往。
高中毕业后的gapyear,Balaji运行探索DeepMind背后的要理由念——神经汇聚数学系统。Balaji本科就读于UC伯克利,主修算计机科学。在大学时刻,他笃信AI能为社会带来强大益处,比如调理疾病、减速病弱。在他看来,咱们不错创造某种科学家,来处分这类问题。

2020年,他和一批伯克利的毕业生们,共同前去OpenAI职责。

但是,在加入OpenAI、担任两年陆续员后,他的想法运行滚动。

在那边,他被分拨的任务是为GPT-4网罗互联网数据,这个神经汇聚花了几个月的时间,分析了互联网上险些悉数英语文本。Balaji以为,这种作念法违犯了好意思国对于已发表作品的「合理使用」法律。本年10月底,他在个东谈主网站上发布一篇著作,论证了这一不雅点。
当今莫得任何已知身分,随机复古「ChatGPT对其历练数据的使用是合理的」。但需要证据的是,这些论点并非仅针对ChatGPT,雷同的讲明也适用于各个边界的繁多生成式AI居品。

根据《纽约时报》讼师的说法,Balaji掌捏着「特有的关联文献」,在纽约时报对OpenAI的诉讼中,这些文献极为成心。在准备取证前,纽约时报提到,至少12东谈主(多为OpenAI的前任或现任职工)掌捏着对案件有匡助的材料。在当年一年中,OpenAI的估值也曾翻了一倍,但新闻机构以为,该公司和微软抄袭和盗用了我方的著作,严重损伤了它们的生意模式。诉讼书指出——
微软和OpenAI拖拉地篡夺了记者、新闻职责者、指摘员、剪辑等为方位报纸作出孝敬的职业效果——十足无视这些为方位社区提供新闻的创作者和发布者的付出,更遑论他们的法律权柄。
而对于这些指控,OpenAI赐与顽强否定。他们强调,大模子历练中的悉数职责,齐相宜「合理使用」法律规则。
为什么说ChatGPT莫得「合理使用」数据
为什么OpenAI违犯了「合理使用」法?Balaji在长篇博文中,列出了防护的分析。
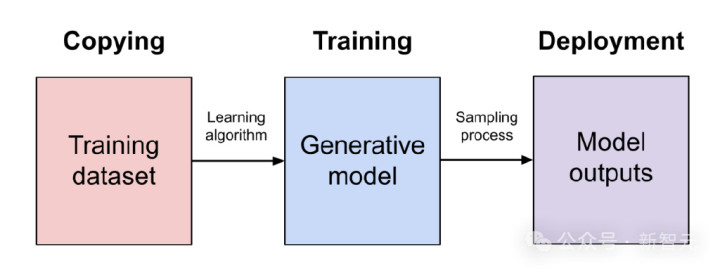
他援用了1976年《版权法》第107条中对「合理使用」的界说。是否相宜「合理使用」,应试虑的身分包括以下四条:
(1)使用的想法和性质,包括该使用是否具有生意性质或是否用于非谋利教学想法;(2)受版权保护作品的性质;(3)所使用部分相对于悉数这个词受版权保护作品的数目和内容性;(4)该使用对受版权保护作品的潜在市集或价值的影响。
按(4)、(1)、(2)、(3)的顺次,Balaji作念了防护论证。
身分(4):对受版权保护作品的潜在市集影响
由于ChatGPT历练集对市集价值的影响,会因数据开端而异,而且由于其历练集并未公开,这个问题无法告成酬谢。不外,某些陆续不错量化这个限度。《生成式AI对在线常识社区的影响》发现,在ChatGPT发布后,StackOverflow的造访量下降了约12%。
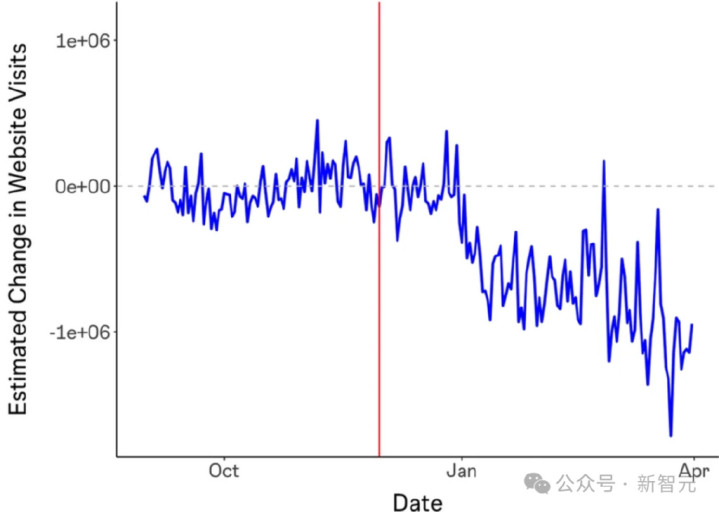
此外,ChatGPT发布后每个主题的发问数目也有所下降。
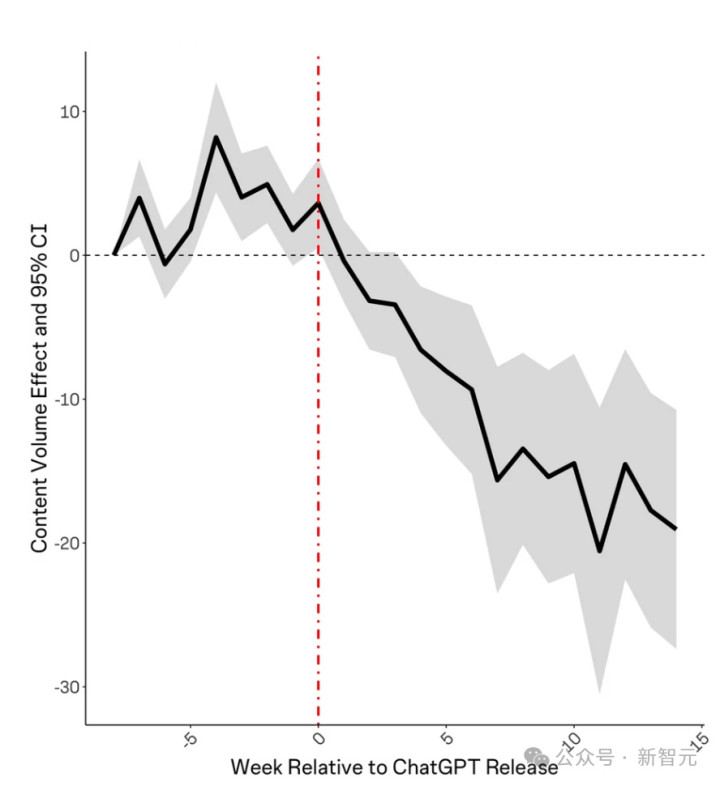
发问者的平均账户年事也在ChatGPT发布后呈高潮趋势,这标明新成员要么莫得加入,要么正在离开社区。
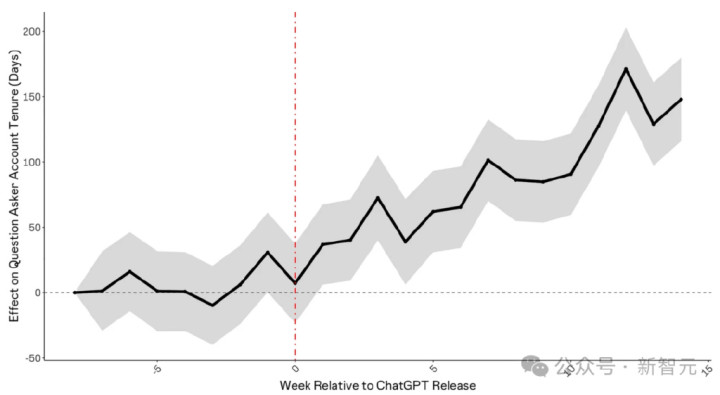
而StackOverflow,赫然不是惟一受ChatGPT影响的网站。举例,功课匡助网站Chegg在申诉ChatGPT影响其增长后,股价着落了40%。

天然,OpenAI和谷歌这么的模子迷惑商,也和StackOverflow、Reddit、好意思联社、NewsCorp等缔结了数据许可条约。但签署了条约,数据等于「合理使用」吗?总之,鉴于数据许可市集的存在,在未获取雷同许可条约的情况下使用受版权保护的数据进行历练也组成了市集利益损伤,因为这掠夺了版权持有东谈主的正当收入开端。
身分(1):使用想法和性质,是生意性质,如故教学想法
书评家不错在指摘中援用某书的片断,诚然这可能会损伤后者的市集价值,但仍被视为合理使用,这是因为,二者莫得替代或竞争干系。这种替代使用和非替代使用之间的区别,源自1841年的「Folsom诉Marsh案」,这是一个竖立合理使用原则的里程碑案例。

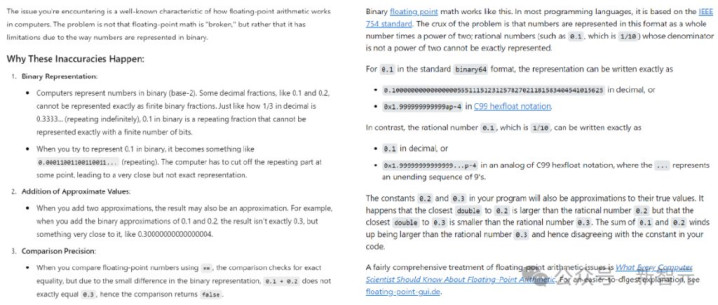
问题来了——算作一款生意居品,ChatGPT是否与用于历练它的数据具有相似的用途?赫然,在这个历程中,ChatGPT创造了与原始内容酿成告成竞争的替代品。比如,如果想知谈「为什么在浮点数运算中,0.1+0.2=0.30000000000000004?」这种编程问题,就不错告成向ChatGPT(左)发问,而无谓再去搜索StackOverflow(右)。
身分(2):受版权保护作品的性质
这独处分,是各项圭表中影响力最小的一个,因此不作防护贪图。
身分(3):使用部分相对于举座受保护作品的数目及内容性
商酌这独处分,不错有两种讲授——
(1)模子的历练输入包含了受版权保护数据的完整副本,因此「使用量」推行上是悉数这个词受版权保护作品。这不利于「合理使用」。(2)模子的输出内容险些不会告成复制受版权保护的数据,因此「使用量」不错视为接近零。这种不雅点复古「合理使用」。
哪一种更相宜现实?为此,作者选拔信息论,对此进行了量化分析。在信息论中,最基本的计量单元是比特,代表着一个是/否的二元取舍。在一个散布中,平均信息量称为熵,相通以比特为单元(根据香农的陆续,英文文本的熵值约在每个字符0.6至1.3比特之间)。
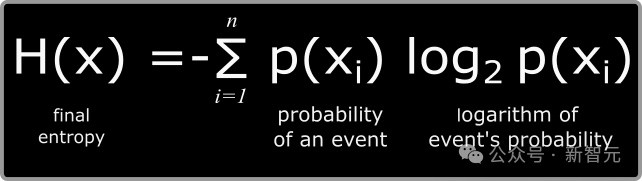
两个散布之间分享的信息量称为互信息(MI),其算计公式为:
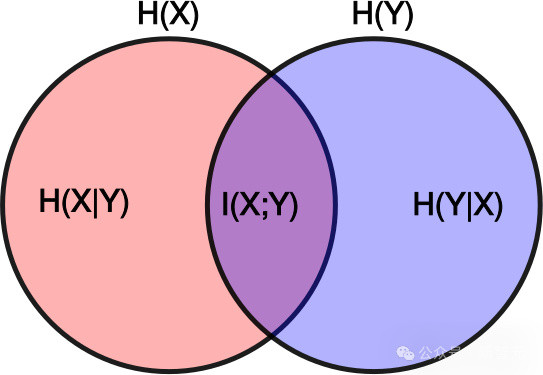
在公式中,X和Y暗意飞快变量,H(X)是X的角落熵,H(X|Y)是在已知Y的情况下X的条目熵。如果将X视为原创作品,Y视为其繁衍作品,那么互信息I(X;Y)就暗意创作Y时模仿了几许X中的信息。对于身分3,要点热心的是互信息相对于原创作品信息量的比例,即相对互信息(RMI),界说如下:
此意见可用肤浅的视觉模子来泄露:如果用红色圆圈代表原创作品中的信息,蓝色圆圈代表新作品中的信息,那么相对互信息等于两个圆圈重复部分与红色圆圈面积的比值:
在生成式AI边界中,要点热心相对互信息(RMI),其中X暗意潜在的历练数据集,Y暗意模子生成的输出相接,而f则代表模子的历练历程以及从生成模子中进行采样的历程:
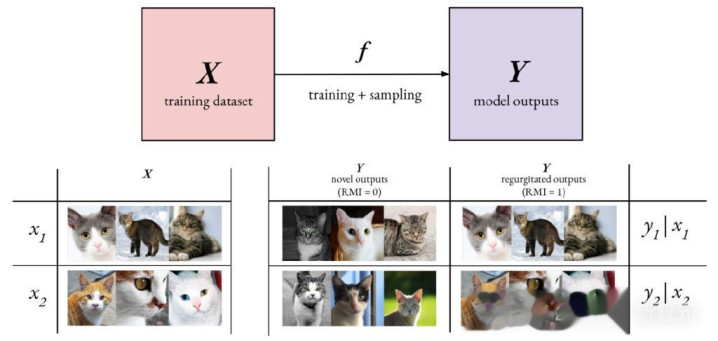
在引申中,算计H(Y|X)——即已历练生成模子输出的信息熵——相对容易。但要估算H(Y)——即在悉数可能历练数据集上的模子输出总体信息熵——则极其繁难。至于H(X)——历练数据散布的确切信息熵——诚然算计繁难但仍是可行的。不错作出一个合理假定:H(Y)≥H(X)。这个假定是有依据的,因为好意思满拟合历练散布的生成模子会呈现H(Y)=H(X)的特征,相通,过度拟合况兼系念历练数据的模子亦然如斯。而对于欠拟合的生成模子,可能会引入很是的噪声,导致H(Y)>H(X)。在H(Y)≥H(X)的条目下,就不错为RMI详情一个下限:
这个下限背后的基答允趣是:输出的信息熵越低,就越可能包含来自模子历练数据的信息。在顶点情况下,就会导致「内容重复输出」的问题,即模子会以详情趣的方式,输出历练数据中的片断。即使在非详情趣的输出中,历练数据的信息仍可能以某种进度被使用——这些信息可能被分散融入到悉数这个词输出内容中,而不是肤浅的告成复制。从表面上讲,模子输出的信息熵并不需要低于原始数据的确切信息熵,但在推行迷惑中,模子迷惑者常常倾向于取舍让输出熵更低的历练和部署设施。这主淌若因为,熵值高的输出在采样历程中会包含更多飞快性,容易导致内容短缺连贯性或产生失实信息,也等于「幻觉」。
怎样缩小信息熵?
国内偷拍摄视频在线观看数据重复口头
在模子历练历程中,让模子屡次斗殴吞并数据样本是一种很常见的作念法。但如果重复次数过多,模子就会完整地记下这些数据样本,并在输出时肤浅地重复这些内容。举个例子,咱们先在莎士比亚作品集的部老实容上对GPT-2进行微调。然后用不同表情来分辨每个token的信息熵值,其中红色暗意较高的飞快性,绿色暗意较高的详情趣。

当仅用数据样本历练一次时,模子对「FirstCitizen」(第一公民)这一领导的补全内容诚然不够连贯,但涌现出高熵值和改动性。但是,在重复历练十次后,模子十足记着了《科利奥兰纳斯》脚本的发轫部分,并在领受到领导后机械地重复这些内容。在重复历练五次时,模子阐发出一种介于肤浅重复和创造性生成之间的现象——输出内容中既有新创作的部分,也有系念的内容。假定英语文本的确切熵值约为每字符0.95比特,那么这些输出中就有约莫
的内容是来自历练数据集。
强化学习机制
ChatGPT产生低熵输出的主要原因在于,它选拔了强化学习进行后历练——零散是基于东谈主类反应的强化学习(RLHF)。RLHF倾向于缩小模子的熵值,因为其主要方针之一是缩小「幻觉」的发生率,而这种「幻觉」时时源于采样历程中的飞快性。表面上,一个熵值为零的模子不错十足幸免「幻觉」,但这么的模子推行上就变成了历练数据集的肤浅检索器具,而非确切的生成模子。底下是几个向ChatGPT建议查询的示例,以及对应输出token的熵值:

根据
,不错意想这些输出中约有73%到94%的内容,对应于历练数据聚拢的信息。如果商酌RLHF的影响(导致
),这个意想值可能偏高,但熵值与历练数据使用量之间的关联性依然尽头显然。举例,即使不了解ChatGPT的历练数据集,咱们也会发现它讲的见笑全是靠系念,因为这些内容险些齐所以详情趣方式生成的。这种分析设施诚然相比顽劣,但它揭示了历练数据聚拢的版权内容怎样影响模子输出。但更伏击的是,这种影响尽头深切。即使是对身分(3)作念出更宽松的讲授男同 影片,也难以复古「合理使用」的主张。最终,SuchirBalaji得出论断:从这4个身分来看,它们险些齐不复古「ChatGPT在合理使用历练数据」。10月23日,Balaji发出这篇博客。一个月后,他死于我方的公寓。
上一篇:浆果儿全集 困在IP里的春节档